
In the first part of this series, we talked about how Notes/Domino environments have been growing organically in companies around the world over decades. We also outlined the role played by “Citizen Developers” in that growth. It’s easy for non-programmers to create their own apps using templates. They can even modify design and functionality without coding.
The result was database/application numbers sky-rocketing in the golden years of Notes. As more templates became available, that development was fueled even further!
The challenge we face in today’s projects isn’t just whether databases are used or not. Project managers and developers have to know the purpose these applications serve, what functions they provide and how they integrate into business processes. Quite the challenge since they probably only use a fraction of those applications personally. One way to tackle this challenge is by taking advantage of the similarity between databases to reduce the amount of effort required.
Only 5-10% of your source code might be unique. So, what?
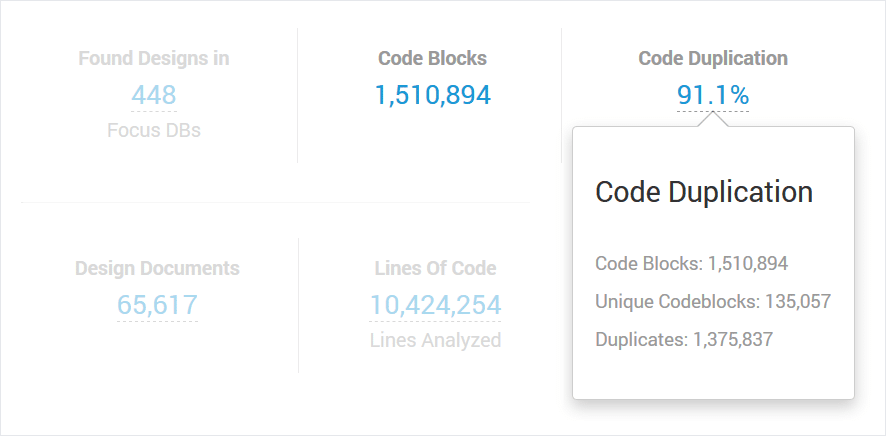
A very high rating of duplicated code is very common in Notes environments. At panagenda we have seen up to 97% code duplication in customer environments.
There’s good reason for such high numbers. Design templates in Domino applications are extensively used. Standard templates like Mail, Discussion and Document libraries are favorites. It makes sense and it should be encouraged. It’s more efficient to incorporate their core functions than it is to continually develop them from scratch.
In fact, once you know where your duplicate code can be found, code duplication can be used to speed up your Notes migration and modernization efforts!

Using cut-and-paste to speed your migration and modernization projects
Not a lot of people are aware of these numbers. How could they be? Information like this is almost impossible to gather. Once you have it though, it can be an extremely powerful tool.
Imagine your developers know all locations of a single code block right from the start. They could write one fix, one time, for one app or template. After that, a simple cut-and-paste can be used to apply that fix wherever it’s needed!
Think of the potential reducing time spent coding when up to 90% of your coding can be done with cut-and-paste! Not only is time and effort reduced significantly, but the skill profile of part of your developers change.
Find your duplicate code – the key to speed
The Source Code dashboard in iDNA quickly shows how much code is duplicated in your environment. You instantly start to have an idea of the potential to speed development in your own environment.
Imagine you are going through a mail migration project. You’re looking for applications that could break when the mail system changes. How can you find that information?
It’s not difficult. Just go to the Database Catalog. Click on the Filter button. Here you can select “Insights”. Insights are potential issues we discovered for you during the source code analysis.
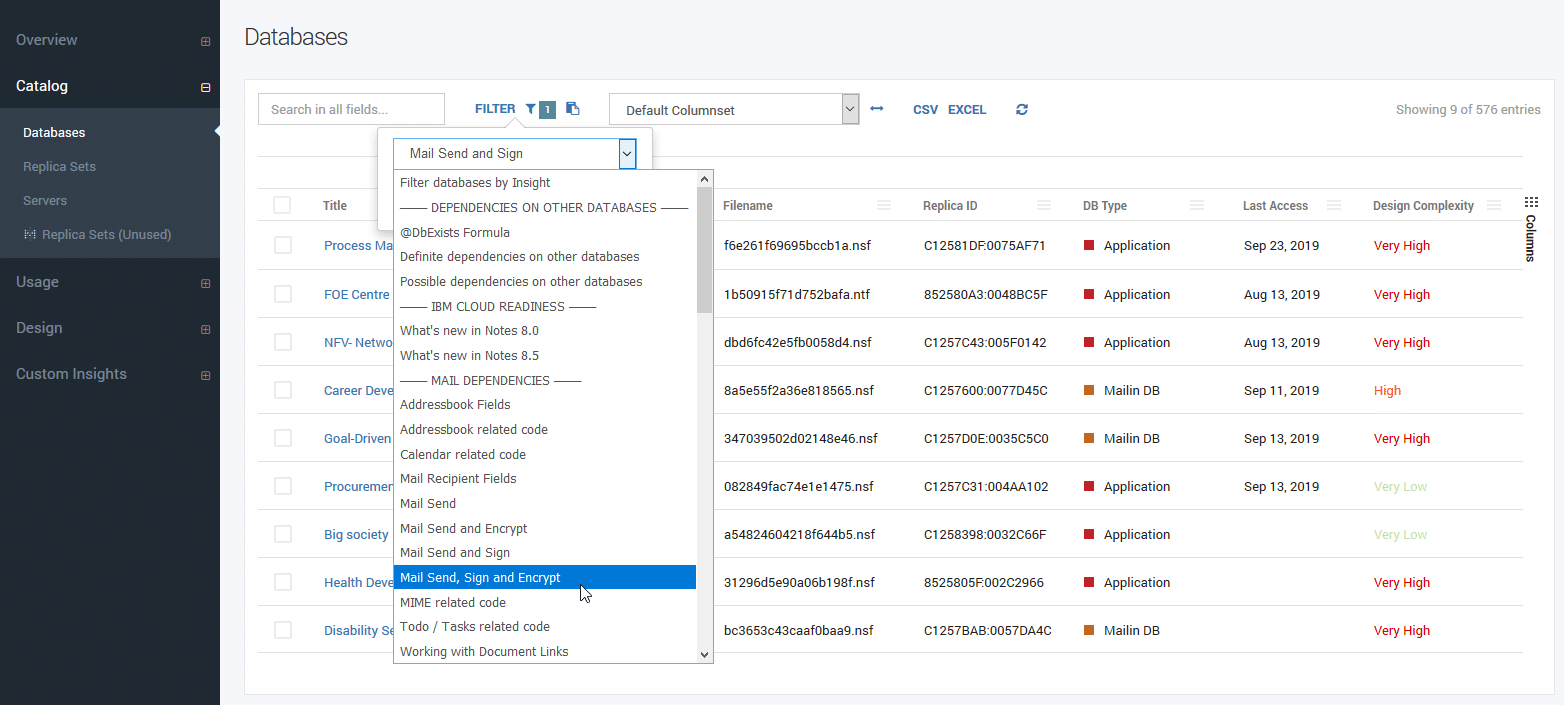
Now you know where your cut-and-paste needs to go
Based on this principle of shared code, iDNA Applications automatically creates “Code Similarity Clusters”. They show which databases share the same source code and how much of that source code they have in common.
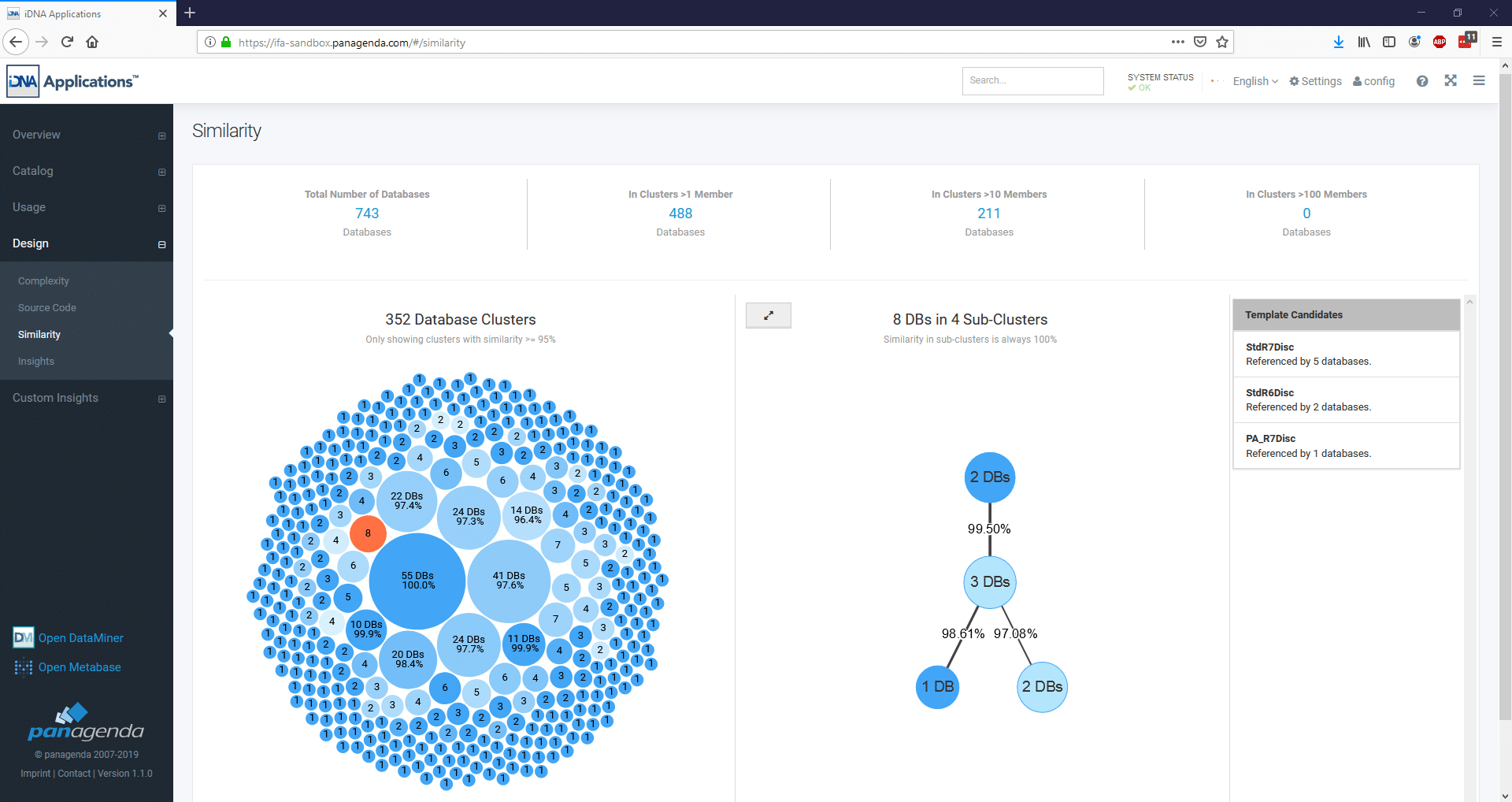
Our experience in customer projects has highlighted three use cases where code duplication and similarity can be utilized for maximum impact:
- Finding the original templates used by applications that do not have an official configured “Master Template”. Knowing which applications share the same internal structure and the degree to which that structure is shared, means you can design one, common roadmap for handling these applications.
- Identifying design differences between template and database instances. Have your applications been modified from their original templates? You’ll want to know! These may require more programming resources to properly process them within your project. Once you know, your developers are where they’re needed, when they’re needed.
- Separating applications based on IBM standard templates from those that are not. Many applications will be based on standard templates. There will already exist developer tools that automate their handing in any project. They tend to be easier and quicker to process.
Don’t worry. It’s taken care of for you. It’s more quick wins without lifting a finger.
Get to know your code before you hit the project road
Having a thorough understanding of your applications and their code creates so many opportunities for you. We’ve only been able to cover a few:
- Save time
- Improve development efficiency
- Reduce costs
- Speed your project
- Improving planning and resource allocation
- Minimize the risk of failure
Take a look at the iDNA Sandbox and see for yourself the possibilities that await you or visit our Knowledge Base for more technical details.
Coming Up in our Series
Now we have a basic understanding of the task ahead in terms of usage and design. The next steps are all about picking the low hanging fruit and identifying potential roadblocks before they become serious issues.
We will discuss the importance of identifying stakeholders, how best to share our success stories and what you need to keep the project scope real.
Register now for the upcoming webinars or watch previous webinars.
About this series:
Many companies around the world have been committed to HCL Notes/Domino* for years. They know the many benefits that come from that relationship. Additionally, Notes/Domino lies at the center of their processes and how they work. Despite all this, IT decisions makers around the world are starting to envision a future where Notes/Domino may play a reduced role or no role at all.
*formerly IBM Notes/Domino
