
Last Friday Microsoft Teams suffered an outage that was felt by organizations and users around the globe. Impacting many features of the Teams application and rendering use of the application mostly useless. Microsoft confirmed that there were problems with the Teams API’s through its Service Health page around 4:42pm CEST (3:42pm UTC). And almost one hour later at 5:45pm CEST (4:45 UTC), Microsoft also confirms the issue, on its X (Twitter) account:
Multiple updates follow, indicating mitigation actions by Microsoft:
Finally reporting:

What was the issue?
In one of the update reports, Microsoft mentions this:
“Our review of service telemetry indicates a portion of database infrastructure that facilitates multiple APIs is experiencing a networking issue, resulting in impact. We’re continuing our investigation to isolate the underlying cause of the networking issue and develop remediation actions.”
How did TrueDEM report on this Incident?
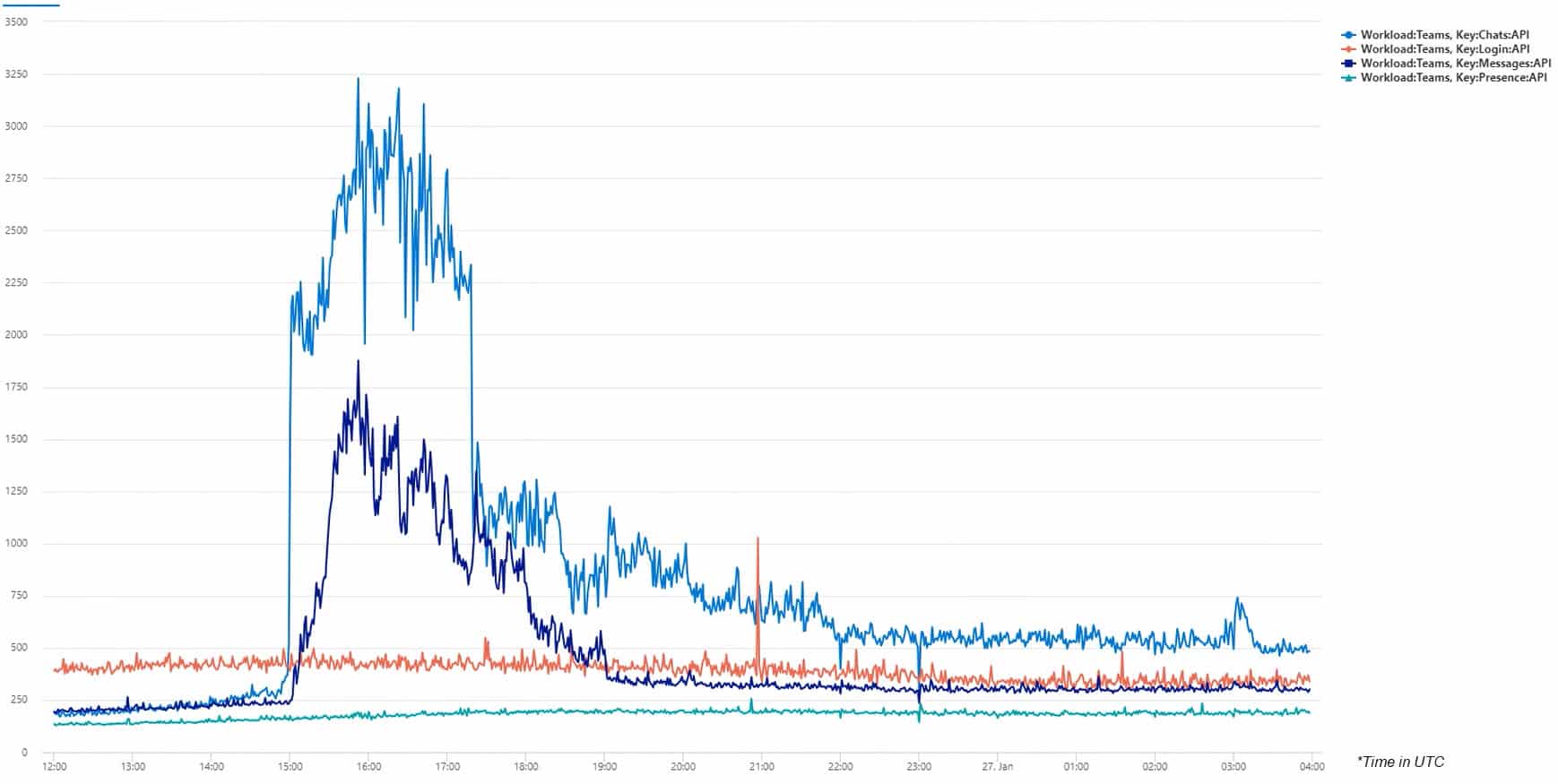
EMEA
Looking at an organization with offices in Europe and the US we can see that nearly two hours before Microsoft sends out the message on X and 45 minutes before the first incident report to acknowledge that something is going on comes through, TrueDEM has already seen it. Around 4pm CEST (3pm UTC) UTC it starts indicating that the response time of the Teams Chats API service skyrockets. Jumping to nearly 3 seconds immediately whereas the Messages API service (dark blue line) starts to increase as well. This lasts until around 11CEST (10pm UTC) when the service performance levels finally reach normal levels of response times.
Other services like Sign-In don’t seem to have been impacted.
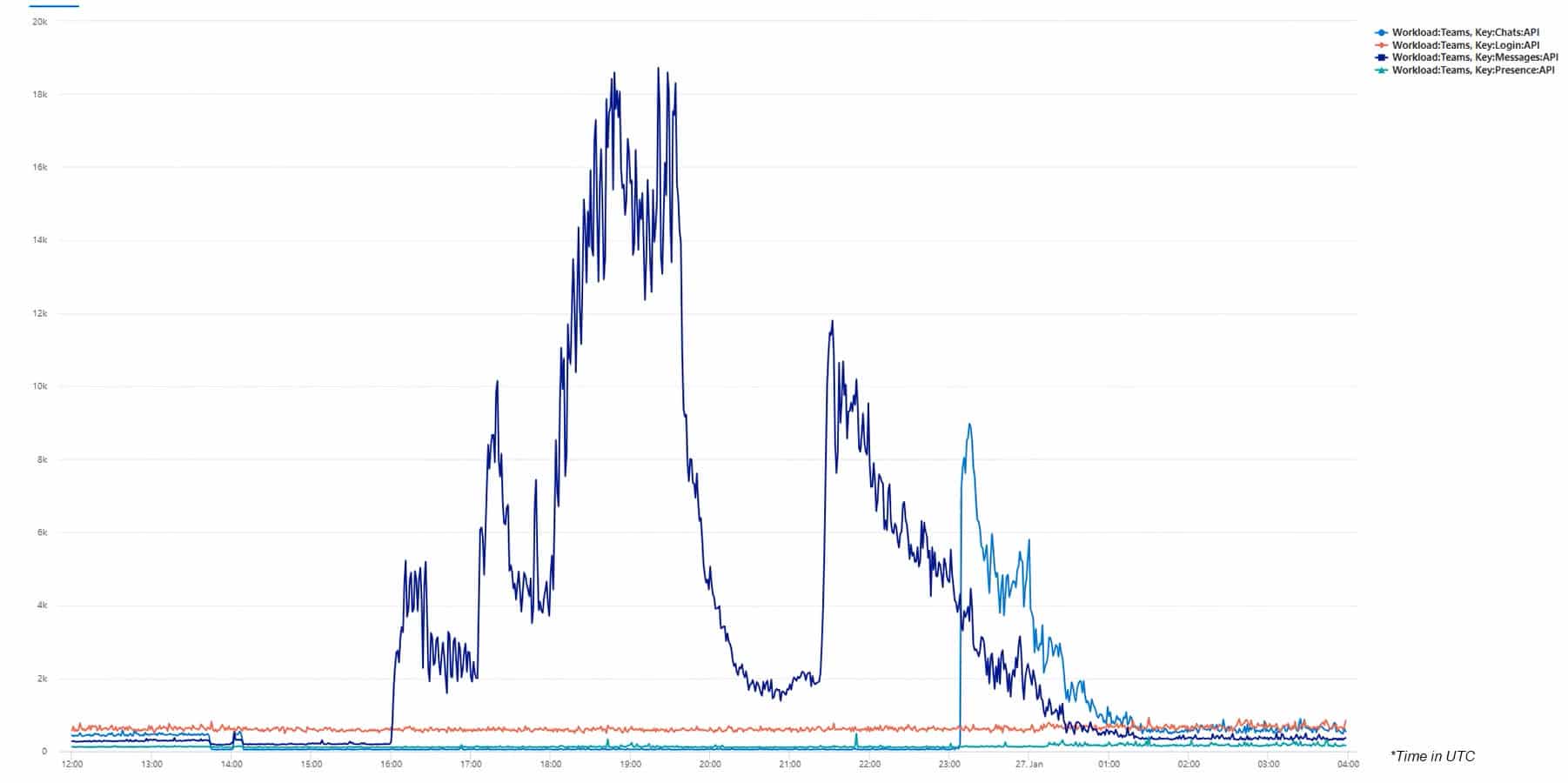
North America
For North America, the picture looks even more severe. Starting nearly an hour later at 4pm UTC (10am EST), it immediately shows a much higher impact compared to Europe. Causing response times for Teams Messages of up to 19 seconds. This continues for hours. Even showing a second flare up around the time the problems in the EU seem to wain off. Until the problems finally gets resolved for the US around 1:30am UTC (7:30pm EST)
Quickly identifying the area of responsibility
As users are starting to notice problems, they start calling support and administrators start investigating. At that moment, TrueDEM is already aware as depicted above. Well before Microsoft acknowledges anything through their channels.
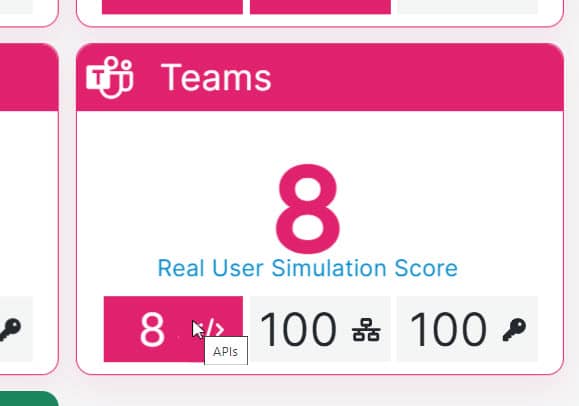
Within 5 minutes of the increase in response time, TrueDEM starts showing the decline of service performance on its Environment Health page. Highlighting that there is a considerable impact on the API. The decline even becomes more outspoken as the impact on the US side starts being noticed. Scoring only 8 out of the 100 (representing the normally expected state for users using Teams in this organization). This clearly indicates that something is going on impacting most, if not all users in the organization. It further pinpoints that the problem is originating on the Microsoft (API) side of things. Not on the Authentication & Network sides which are both still scoring normal (100).
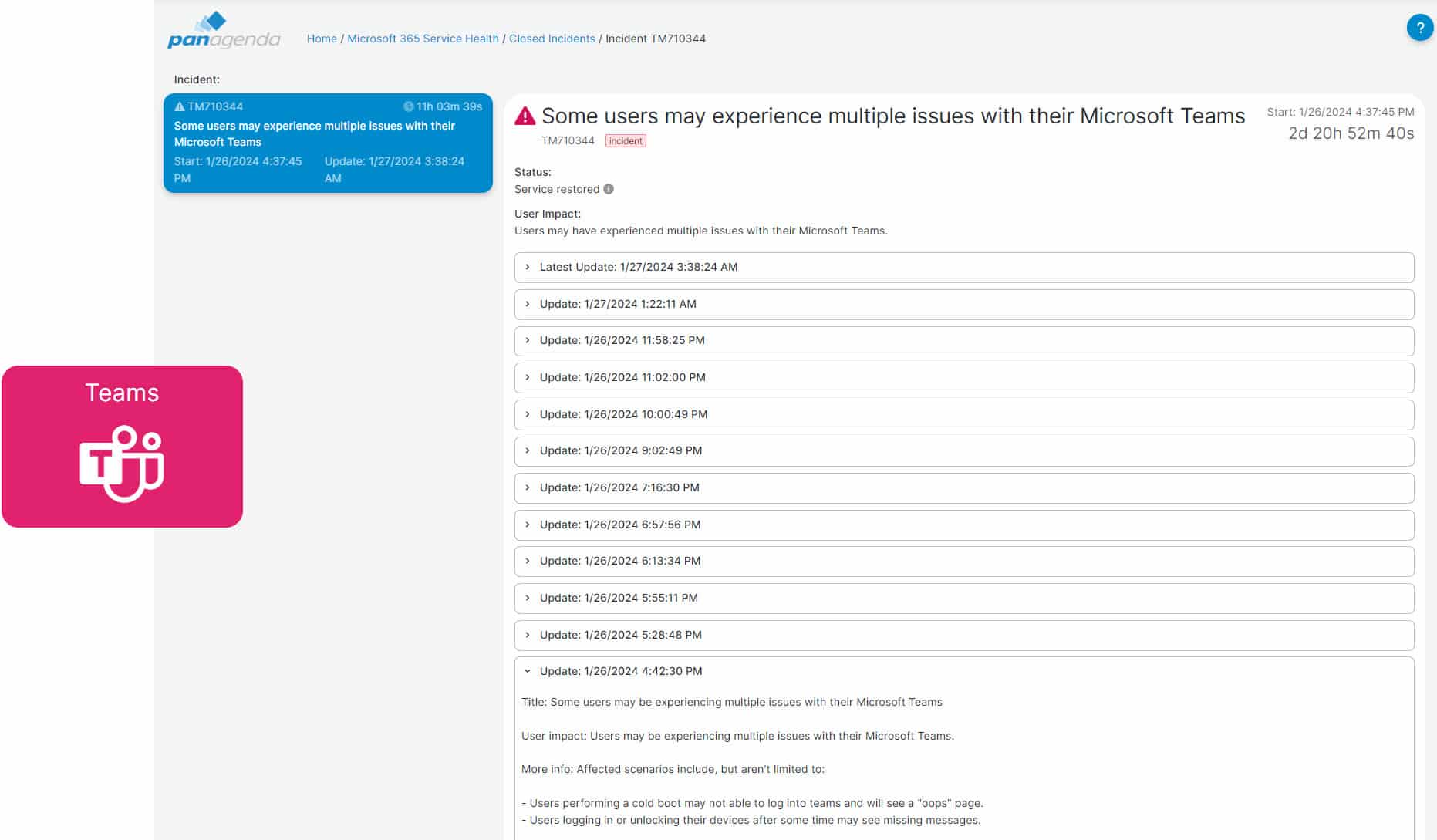
Microsoft then sends out its initial incident report 45 minutes later. This is reflected immediately on the Microsoft Health page in TrueDEM. On this page TrueDEM shows all Microsoft reported incidents and alerts relevant to the specific organization. Adding the Microsoft incident updates as they get posted in a focused and easily navigable overview until the issue is closed by Microsoft 2 days later:
Bottom Line
Any disturbance to Microsoft Teams can have a major impact on the operations of organizations. Being able to quickly identify that the problem was Microsoft API related made it possible for admins using TrueDEM to see immediately that the likely cause was with the Microsoft cloud itself. Eliminating unnecessary research into potential causes. Focusing in on specific networks and ISP’s, they could even track as services got restored in Europe first and the US later.
- The issue was first noticeable in Europe having a big impact on, among others, the response times of chats & messages.
- The issue hit North America nearly an hour later but the effect there was even more severe with response times up to 19 seconds and lasting much longer.
- TrueDEM saw and reported the issue 42min before Microsoft acknowledged the incident via their Service Health and 1:45 hours before they send out the first tweet on X.
- With TrueDEM, admins were able to see the effects of Microsoft’s ongoing mitigations to their specific organization and users across various regions much more directly than what was being communicated by Microsoft through its X and service health channels.
